Automatic Annotation of Danish Chest X-ray Reports
Project by Lea Marie Pehrson and Alice Schiavone
This project explores the use of Natural Language Processing (NLP) to automate the annotation of Danish chest X-ray reports. By leveraging Artificial Intelligence (AI) -driven techniques, it aims to extract structured labels from free-text radiology reports, reducing the need for time-consuming manual annotations. This automated process is a crucial step toward developing an image classifier for thoracic X-rays, enhancing diagnostic workflows and improving accessibility to high-quality labeled datasets in non-English clinical settings.
Project BackgroundDeveloping AI models for medical imaging requires large, well-annotated datasets. However, manual annotation by radiologists is both expensive and time-consuming. This challenge is especially significant in smaller languages such as Danish, where there are few tools available for the automated extraction of structured medical data.
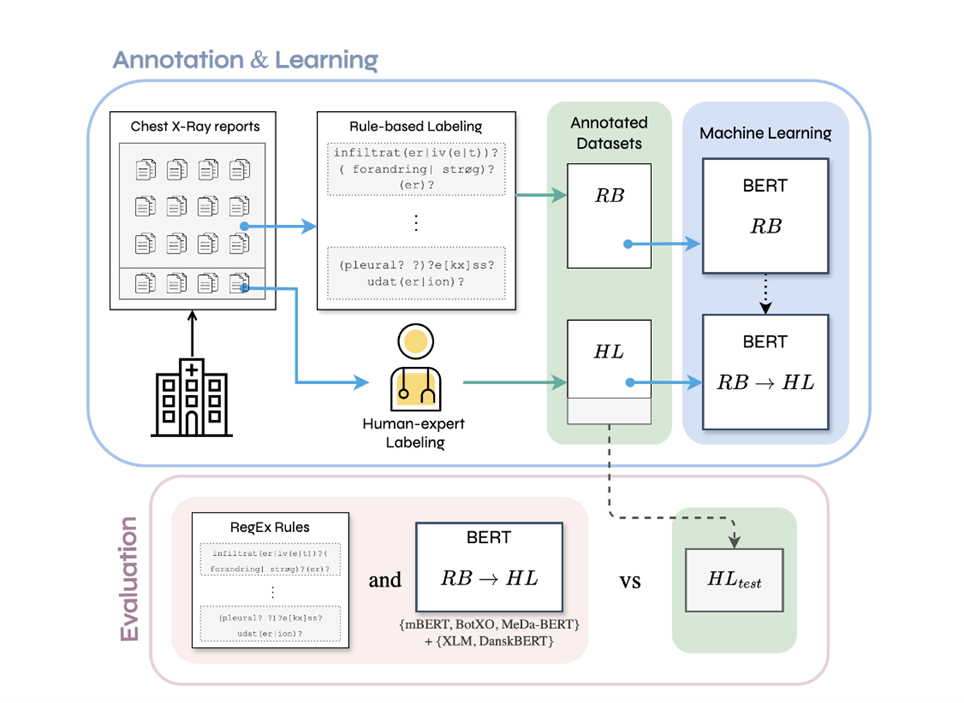
To address this, the project employs NLP techniques to extract structured labels from free-text X-ray reports. The approach consists of three key steps:
Rule-Based Labeling (RegEx): A set of rules are used to identify key medical findings and their negations. Machine Learning-Based Labeling (BERT): Several BERT-based models, including Danish medical BERT (MeDa-BERT) and XLM-RoBERTa, are fine-tuned to classify findings. Comparison & Evaluation: Rule-based and machine learning labeling approaches are compared to determine their effectiveness, accuracy, and resource requirements.Through this comparison, the project aims to establish the most effective strategy for automating medical report annotation in Danish, providing a foundation for further AI-driven advancements in medical annotation.
Project PotentialThe findings from this project have important implications for clinical AI development, especially in non-English medical settings. The key contributions include:
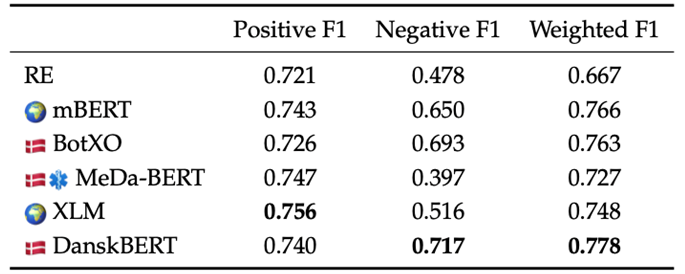
- Performance of NLP in Medical Danish: The project demonstrated that Danish BERT-based models perform better than rule-based methods, particularly for identifying negative findings.
- Application Beyond Danish Radiology Reports: These methods could also be applied to other medical datasets in non-English languages, promoting wider adoption of AI in healthcare.
- Comparison & Evaluation: Rule-based and machine learning labeling approaches are compared to determine their effectiveness, accuracy, and resource requirements.
Despite these achievements, certain challenges remain, particularly in handling variation within Danish medical terminology and the limited availability of publicly accessible datasets. Addressing these will be crucial for further model improvements and clinical integration.